
この記事は、YouTubeでもご覧いただけます。映像とナレーションで内容がよりわかりやすく解説されているので、ぜひ以下のリンクからご覧ください。
■【競馬予想AIを学ぶ】LightGBMによるAI競馬予想(二値分類)
https://youtu.be/9PTmwPaFIh4
チャンネルは姉妹サイト「PC-KEIBA」のものですが、競艇に関連する内容に置き換えて楽しんでいただけます。
この記事を読む前に「LightGBMによるAI競艇予想(準備編)」の記事を先に読んでください。その中には、機械学習の基礎知識や、学習データで使う説明変数の内容など、他のデータ分析方法と共通する説明が含まれています。
二値分類(binary)
「二値分類」は目的変数を0か1の二値に分類する方法です。
ここに公開するPythonのソースコードは「正解率・適合率・再現率・F値・AUC」の評価指標と「特徴量重要度」の可視化を実装しています。学習データを作るSQLで目的変数の項目名を「target」にすれば、オリジナルの学習データで分析する場合でもそのまま使えます。
ソースコードは学習用と予測用に分けてます。
欠損値(null)は、SQLで何らかの値(0など)に変換しておくことを前提にしてます。欠損値についてPythonでは何もしてないってことです。
学習用ソースコード
以下が「二値分類」で学習するPythonのソースコードです。この学習用ソースコードのファイル名は「binary_train.py」とします。
PythonのソースコードはUTF-8で保存する必要があります。何のこっちゃ分からん場合は、このページの最後の、有料会員限定のダウンロードリンクからもファイルをダウンロードできます。
ソースコードはQiitaの記事から簡単にコピーできます。
※ソースコードの右上に出るアイコンをクリックしてください。
https://qiita.com/PC-KYOTEI/items/5fe6126e3abb6a4a3628
import pandas as pd
import numpy as np
import lightgbm as lgb
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score
# CSVファイル読み込み
in_file_name = 'binary_train.csv'
df = pd.read_csv(in_file_name, encoding='SHIFT_JIS')
# 説明変数(x)と目的変数(y)を設定
target = 'target'
x = df.drop(target, axis=1).values # y以外の特徴量
y = df[target].values
# 説明変数の項目名を取得
feature = list(df.drop(target, axis=1).columns)
# 訓練データとテストデータを分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0)
# LightGBM ハイパーパラメータ
params = {
'objective':'binary', # 目的 : 二値分類
'metric':'binary_error' # 評価指標 : 正答率
}
# モデルの学習
train_set = lgb.Dataset(x_train, y_train)
valid_sets = lgb.Dataset(x_test, y_test, reference=train_set)
model = lgb.train(params, train_set=train_set, valid_sets=valid_sets)
# モデルをファイルに保存
model.save_model('binary_model.txt')
# テストデータの予測
y_prob = model.predict(x_test)
y_pred = np.where(y_prob < 0.5, 0, 1)
# 評価指標
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, y_pred)
print('正解率 = ', accuracy)
print('適合率 = ', precision)
print('再現率 = ', recall)
print('F値 = ', f1)
print('AUC = ', roc_auc)
# 特徴量重要度
importance = np.array(model.feature_importance())
df = pd.DataFrame({'feature':feature, 'importance':importance})
df = df.sort_values('importance', ascending=True)
n = len(df) # 説明変数の項目数を取得
values = df['importance'].values
plt.barh(range(n), values)
values = df['feature'].values
plt.yticks(np.arange(n), values) # x, y軸の設定
plt.savefig('binary_train.png', bbox_inches='tight', dpi=500)
plt.show()学習データを作る
説明変数は他の分析方法と共通にしました。内容は「LightGBMによるAI競艇予想(準備編)」の記事を見てください。学習データのファイル名は「binary_train.csv」とします。
今回のサンプルでは目的変数の「着順」を、次のように分類してみます。
- 3着以内→1
- 上記以外→0
このページの最後に、サンプルのSQLを有料会員に公開しています。ユーザーがカスタマイズして利用することも可能ですし、SQLを学習したい方の参考にもなります。
LightGBMに学習させる
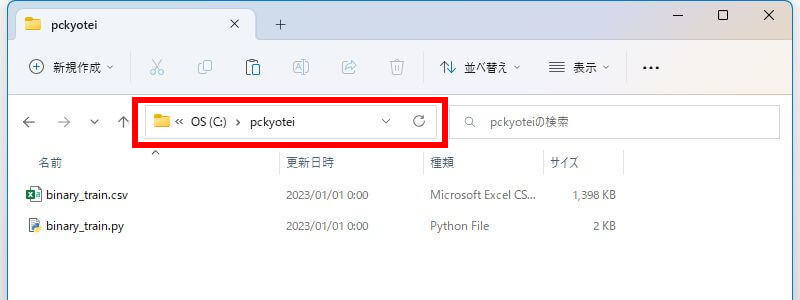
今回の例では、Cドライブの直下に「pckyotei」というフォルダを作って、
- 学習データ(binary_train.csv)
- 学習用ソースコード(binary_train.py)
2つのファイルを置きます。こういう状態です。
そして、コマンドプロンプトを起動し、次の2つのコマンドを「1行ずつ」実行してください。
cd C:\pckyoteipython binary_train.pyLightGBMが学習を開始します。処理が終わると評価指標を表示します。
モデルを評価する
今回のサンプルでは、次の3つの評価指標を表示します。
- 「正解率」= 全てのサンプルを正解した割合
- 「適合率」= 1と予測したサンプルのうち、実際に1であった割合
- 「再現率」= 実際に1であるサンプルのうち、1と予測した割合
- 「F値」= 適合率と再現率の調和平均を表す指標
- 「AUC」= ROC曲線の下の面積を示し、1に近いほど分類精度が高い
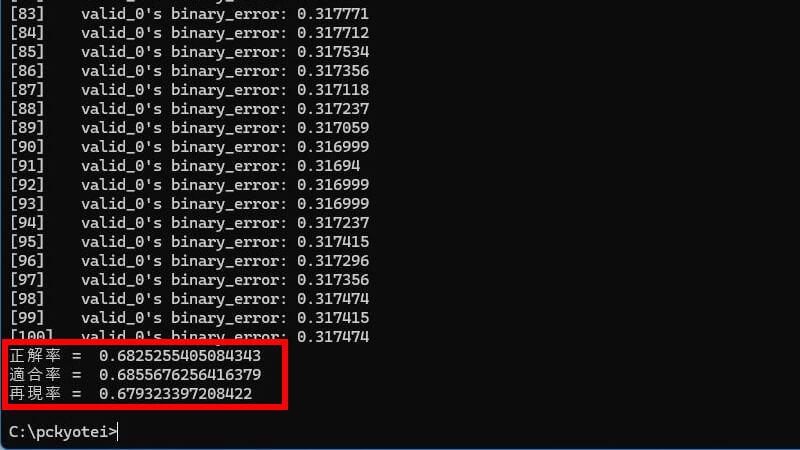
今回のモデルでは、このような結果になりました。これを競艇場ごとに分析したら、もっと精度の高いモデルに出来るかもしれません。二値分類の評価指標は、この他にもあるのでググって研究してください。
このモデルを「binary_model.txt」に保存しています。このファイルは予想するとき使います。
特徴量重要度
参考として「特徴量重要度」の可視化を実装してます。特徴量重要度をざっくり言うと、重要度が高い説明変数ほど、目的変数である着順に対して影響力が強いということです。
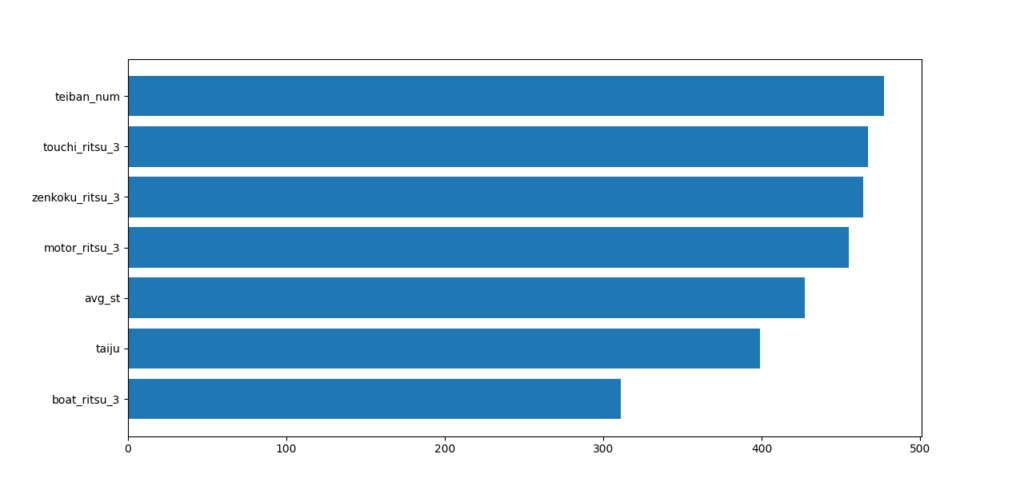
これを見ながら説明変数を取捨選択したり、LightGBMパラメータをチューニングしたりします。
今回のモデルによる結果であるため、この結果がすべてのレースに当てはまると言うわけじゃないです。
いろいろ試してモデルの精度に納得したら、これを使って明日のレースを予想させます。
予測用ソースコード
以下が「二値分類」で予想するPythonのソースコードです。
PythonのソースコードはUTF-8で保存する必要があります。何のこっちゃ分からん場合は、このページの最後の、有料会員限定のダウンロードリンクからもファイルをダウンロードできます。
ソースコードはQiitaの記事から簡単にコピーできます。
※ソースコードの右上に出るアイコンをクリックしてください。
https://qiita.com/PC-KYOTEI/items/5fe6126e3abb6a4a3628
import pandas as pd
import numpy as np
import lightgbm as lgb
import os
import sys
# 出走表ファイル読み込み
fname = sys.argv[1]
x_test = np.loadtxt(fname, delimiter=',', skiprows=1)
# 1行だけの場合でも2次元配列に変換
if x_test.ndim == 1:
x_test = x_test.reshape(1, -1)
# モデル読み込み
bst = lgb.Booster(model_file='binary_model.txt')
# データの予測
y_prob = bst.predict(x_test, num_iteration=bst.best_iteration)
y_pred = np.where(y_prob < 0.5, 0, 1)
# 拡張子を除いたファイル名を取得
fname = os.path.splitext(os.path.basename(fname))[0]
# 予測値を出力
df = pd.DataFrame({'予測値':y_pred})
df.to_csv(fname + '_pred.csv', encoding='SHIFT_JIS', index=False)
# 予測確率を出力
df = pd.DataFrame({'0の確率':1 - y_prob, '1の確率':y_prob})
df.to_csv(fname + '_prob.csv', encoding='SHIFT_JIS', index=False)出走表データを作る
予測させる出走表データは、学習データ作成のSQLと出力後のファイルを少し改造すれば作れます。学習データとの違いは次の2つです。
- SQLで目的変数「target」の項目を消す。
- SQLで予想するレースでレコードの抽出条件を設定する。
出走表データのファイル名は何でも良いですが、ここでは「レースID(※1).csv」とします。
今回のサンプルでは「2022/10/25(火)常滑12R 第69回ボートレースダービー(SG)」を予想してみます。
| (※1)レースID | 年月日場R yyyymmddjjrr(12桁) |
|---|
このページの最後に、サンプルのSQLを有料会員に公開しています。ユーザーがカスタマイズして利用することも可能ですし、SQLを学習したい方の参考にもなります。
予測(予想)させる
先ほどと同じ「pckyotei」というフォルダに、
- 出走表(レースID(※1).csv)
- モデル(binary_model.txt)
- 予測用ソースコード(binary_pred.py)
3つのファイルを置きます。こういう状態です。
そして、コマンドプロンプトを起動し、次の2つのコマンドを「1行ずつ」実行してください。2番目は、予測用ソースコードの後に、半角スペースと出馬表のファイル名です。
cd C:\pckyoteipython binary_pred.py 202210250812.csv処理が終わると2つのファイルが出力されます。「予測値」と「確率」のファイルです。
- レースID(※1)_pred.csv (予測値)
- レースID(※1)_prob.csv (確率)
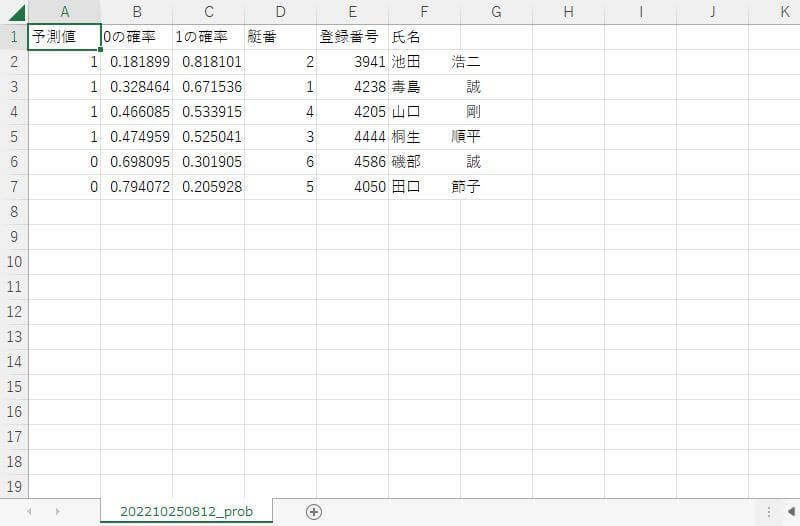
このファイルには数値データしか含まれていないので、分かりにくいかもしれませんが、出走表データと同じ艇番の昇順で出力されます。舟券を買うときは、SQLで艇番とレーサー氏名だけの出走表をCSVに出力して、そこへ貼り付けて確率で並べ替えると便利です。例えば、こんな感じです。
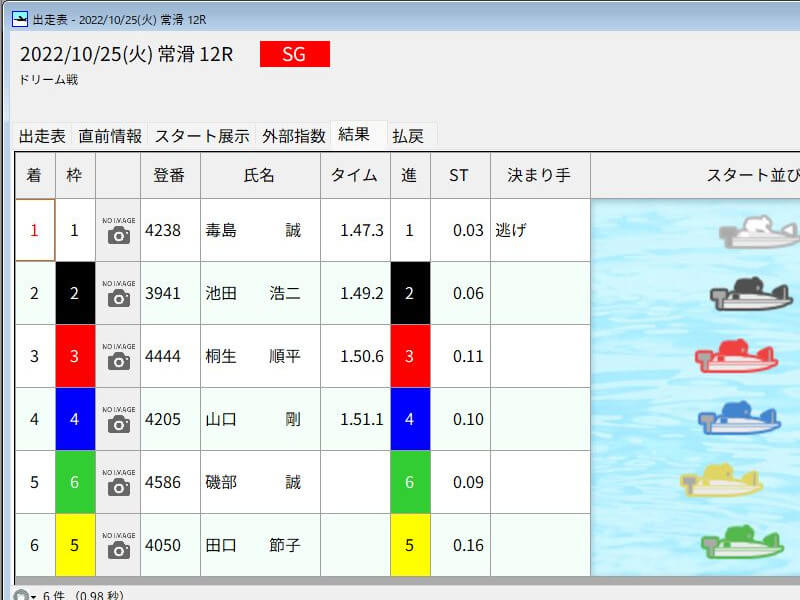
「予測値=1」の4艇で、レース結果は3連複の払戻金が470円となりました。
「二値分類」による競艇予想AIの話は以上です。
今回のサンプルはあくまで1つの「サンプル」でしかありません。完成させるのはユーザーのあなたです。
